Kenome
After leaving MathWorks, I joined Kenome to follow my interest of pursuing research in Machine Learning and NLP. The company, founded by Dr. Talukdar – assistant professor in The Department of Computational and Data Sciences at IISc, Bangalore – sits in the space between research and industry. The company was just a couple of months old when I joined in February 2018 and I was given the responsibility of developing predictive models for all kinds of time-series data like stock prices (real-valued data), items demand (positive count valued data), by using structured (usual time-series data) as well as unstructured data (text data like tweets, blogs, etc.)
Starting from literature survey, I developed state of the art, scalable and versatile, recurrent neural network based model for timeseries predictions, called KIP-Timeseries. The highlights of the model are its:
-
Versatility: It can be used for prediction of all kinds of timeseries data ranging from demand forecasting to stock-market price prediction,
-
Scalability: It can be scaled to include any number of structured and unstructured data source,
-
Usefulness: It provides probabilistic predictions instead of point predictions. These can be used to make more informed decisions in various real-life business scenarios.
Using KIP-Timeseries and KIP-Social Sensing (an aggregate sentiment analyser which we developed at Kenome), we (a team of three engineers) developed a crypto-currency price prediction tool called TrakCrypto – one of the first Kenome product deployed at an enterprise level. The model and the platform is constantly being improved.
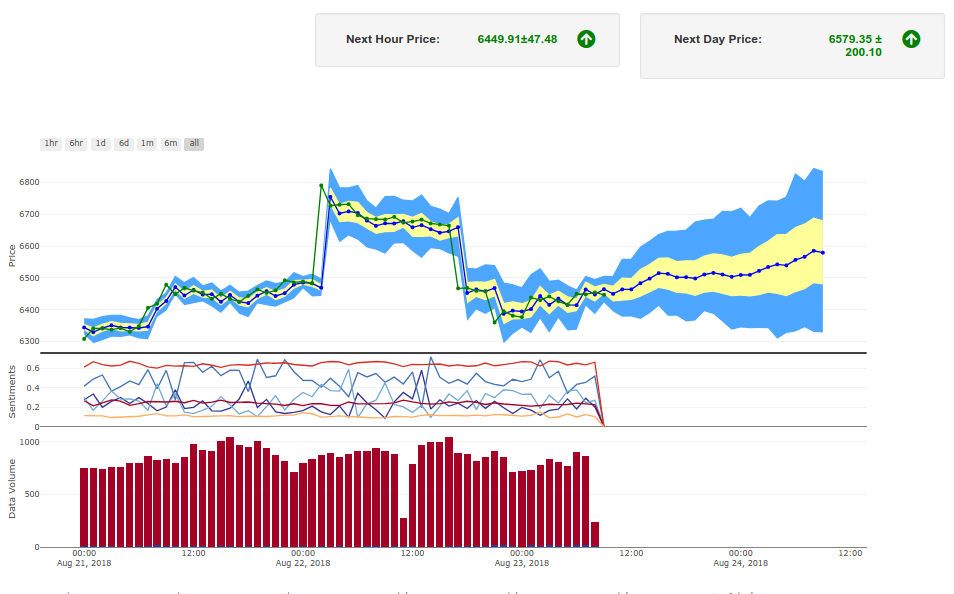
Also worked in a small team developing Kenome Insights Platform (KIP), a set of end-to-end pipelines for various Machine Learning tasks. It consists of data collection, data storage, ML models and deployment pipelines. In particular, I have developed a deep transfer-learning based model for the sentiment analysis of financial news headlines. Following are the libraries/frameworks I have been using in my work at Kenome:
Since I was one of the first few engineers at Kenome, I was involved in selection of organization wide development tools and workflows: code style, issue tracking, testing, deployment, etc. and various other engineering decisions which are generally exclusively handled by senior managers in big companies. This additional responsibility and exposure to end-to-end development cycle of data centric software has provided me with the confidence to handle much bigger projects in future.